Tips
2023-4-1 21点29分这几天搞了两个BB企业版的壳学到一丢丢东西- 一个从
java层扣出来的代码 转换为 Python 代码之后 第一次new返回的结果就是对的 第二次调用就报错 - 我也没去分析 后面看了人家
java层代码发现 他每次都new一个新的 如果重复用旧对象就会导致乱码 当时也是莫名其妙
- 一个从
def __init__(self):
message_digest = hashlib.sha256()
message_digest.update(self.SEED_16_CHARACTER.encode("utf-8"))
key_bytes = message_digest.digest()[:32]
self.cipher = AES.new(key_bytes, AES.MODE_CBC, iv=bytes(16))
def decrypt(self, _encrypted_text):
encrypted_data = base64.b64decode(_encrypted_text.encode("utf-8"))
decrypted_data = self.cipher.decrypt(encrypted_data)
return unpad(decrypted_data, AES.block_size).decode("utf-8")- 第二个就是 相同的参数 在
apiFoxjava发包都可以 在Python就显示有风险- 第一时间想到的就是
TLS然后有个大佬发了一下 最简单的requests发包软件都可以发包成功 这就蒙了 - 到后面发现是因为
Python的Json.dumps的对象是{"req" : "****"}而java是{"req":"****"}中间没有空格 该死的 后面删掉就好了 - 推荐以后直接替换
json.dumps({"req": "****"}).replace(" ", '')
- 第一时间想到的就是
AndroidBase64
- 经常会遇到
app调用Android的Base64所以直接把源码复制出来保存在这吧
package Hook.obj;
import java.io.UnsupportedEncodingException;
/**
* Utilities for encoding and decoding the Base64 representation of
* binary data. See RFCs <a
* href="http://www.ietf.org/rfc/rfc2045.txt">2045</a> and <a
* href="http://www.ietf.org/rfc/rfc3548.txt">3548</a>.
*/
public class AndroidBase64 {
/**
* Default values for encoder/decoder flags.
*/
public static final int DEFAULT = 0;
/**
* Encoder flag bit to omit the padding '=' characters at the end
* of the output (if any).
*/
public static final int NO_PADDING = 1;
/**
* Encoder flag bit to omit all line terminators (i.e., the output
* will be on one long line).
*/
public static final int NO_WRAP = 2;
/**
* Encoder flag bit to indicate lines should be terminated with a
* CRLF pair instead of just an LF. Has no effect if {@code
* NO_WRAP} is specified as well.
*/
public static final int CRLF = 4;
/**
* Encoder/decoder flag bit to indicate using the "URL and
* filename safe" variant of Base64 (see RFC 3548 section 4) where
* {@code -} and {@code _} are used in place of {@code +} and
* {@code /}.
*/
public static final int URL_SAFE = 8;
/**
* Flag to pass to {@link } to indicate that it
* should not close the output stream it is wrapping when it
* itself is closed.
*/
public static final int NO_CLOSE = 16;
// --------------------------------------------------------
// shared code
// --------------------------------------------------------
/* package */ static abstract class Coder {
public byte[] output;
public int op;
/**
* Encode/decode another block of input data. this.output is
* provided by the caller, and must be big enough to hold all
* the coded data. On exit, this.opwill be set to the length
* of the coded data.
*
* @param finish true if this is the final call to process for
* this object. Will finalize the coder state and
* include any final bytes in the output.
* @return true if the input so far is good; false if some
* error has been detected in the input stream..
*/
public abstract boolean process(byte[] input, int offset, int len, boolean finish);
/**
* @return the maximum number of bytes a call to process()
* could produce for the given number of input bytes. This may
* be an overestimate.
*/
public abstract int maxOutputSize(int len);
}
// --------------------------------------------------------
// decoding
// --------------------------------------------------------
/**
* Decode the Base64-encoded data in input and return the data in
* a new byte array.
*
* <p>The padding '=' characters at the end are considered optional, but
* if any are present, there must be the correct number of them.
*
* @param str the input String to decode, which is converted to
* bytes using the default charset
* @param flags controls certain features of the decoded output.
* Pass {@code DEFAULT} to decode standard Base64.
* @throws IllegalArgumentException if the input contains
* incorrect padding
*/
public static byte[] decode(String str, int flags) {
return decode(str.getBytes(), flags);
}
/**
* Decode the Base64-encoded data in input and return the data in
* a new byte array.
*
* <p>The padding '=' characters at the end are considered optional, but
* if any are present, there must be the correct number of them.
*
* @param input the input array to decode
* @param flags controls certain features of the decoded output.
* Pass {@code DEFAULT} to decode standard Base64.
* @throws IllegalArgumentException if the input contains
* incorrect padding
*/
public static byte[] decode(byte[] input, int flags) {
return decode(input, 0, input.length, flags);
}
/**
* Decode the Base64-encoded data in input and return the data in
* a new byte array.
*
* <p>The padding '=' characters at the end are considered optional, but
* if any are present, there must be the correct number of them.
*
* @param input the data to decode
* @param offset the position within the input array at which to start
* @param len the number of bytes of input to decode
* @param flags controls certain features of the decoded output.
* Pass {@code DEFAULT} to decode standard Base64.
* @throws IllegalArgumentException if the input contains
* incorrect padding
*/
public static byte[] decode(byte[] input, int offset, int len, int flags) {
// Allocate space for the most data the input could represent.
// (It could contain less if it contains whitespace, etc.)
Decoder decoder = new Decoder(flags, new byte[len * 3 / 4]);
if (!decoder.process(input, offset, len, true)) {
throw new IllegalArgumentException("bad base-64");
}
// Maybe we got lucky and allocated exactly enough output space.
if (decoder.op == decoder.output.length) {
return decoder.output;
}
// Need to shorten the array, so allocate a new one of the
// right size and copy.
byte[] temp = new byte[decoder.op];
System.arraycopy(decoder.output, 0, temp, 0, decoder.op);
return temp;
}
/* package */ static class Decoder extends Coder {
/**
* Lookup table for turning bytes into their position in the
* Base64 alphabet.
*/
private static final int DECODE[] = {
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -2, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
};
/**
* Decode lookup table for the "web safe" variant (RFC 3548
* sec. 4) where - and _ replace + and /.
*/
private static final int DECODE_WEBSAFE[] = {
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -2, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, 63,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
};
/**
* Non-data values in the DECODE arrays.
*/
private static final int SKIP = -1;
private static final int EQUALS = -2;
/**
* States 0-3 are reading through the next input tuple.
* State 4 is having read one '=' and expecting exactly
* one more.
* State 5 is expecting no more data or padding characters
* in the input.
* State 6 is the error state; an error has been detected
* in the input and no future input can "fix" it.
*/
private int state; // state number (0 to 6)
private int value;
final private int[] alphabet;
public Decoder(int flags, byte[] output) {
this.output = output;
alphabet = ((flags & URL_SAFE) == 0) ? DECODE : DECODE_WEBSAFE;
state = 0;
value = 0;
}
/**
* @return an overestimate for the number of bytes {@code
* len} bytes could decode to.
*/
public int maxOutputSize(int len) {
return len * 3 / 4 + 10;
}
/**
* Decode another block of input data.
*
* @return true if the state machine is still healthy. false if
* bad base-64 data has been detected in the input stream.
*/
public boolean process(byte[] input, int offset, int len, boolean finish) {
if (this.state == 6) return false;
int p = offset;
len += offset;
// Using local variables makes the decoder about 12%
// faster than if we manipulate the member variables in
// the loop. (Even alphabet makes a measurable
// difference, which is somewhat surprising to me since
// the member variable is final.)
int state = this.state;
int value = this.value;
int op = 0;
final byte[] output = this.output;
final int[] alphabet = this.alphabet;
while (p < len) {
// Try the fast path: we're starting a new tuple and the
// next four bytes of the input stream are all data
// bytes. This corresponds to going through states
// 0-1-2-3-0. We expect to use this method for most of
// the data.
//
// If any of the next four bytes of input are non-data
// (whitespace, etc.), value will end up negative. (All
// the non-data values in decode are small negative
// numbers, so shifting any of them up and or'ing them
// together will result in a value with its top bit set.)
//
// You can remove this whole block and the output should
// be the same, just slower.
if (state == 0) {
while (p + 4 <= len &&
(value = ((alphabet[input[p] & 0xff] << 18) |
(alphabet[input[p + 1] & 0xff] << 12) |
(alphabet[input[p + 2] & 0xff] << 6) |
(alphabet[input[p + 3] & 0xff]))) >= 0) {
output[op + 2] = (byte) value;
output[op + 1] = (byte) (value >> 8);
output[op] = (byte) (value >> 16);
op += 3;
p += 4;
}
if (p >= len) break;
}
// The fast path isn't available -- either we've read a
// partial tuple, or the next four input bytes aren't all
// data, or whatever. Fall back to the slower state
// machine implementation.
int d = alphabet[input[p++] & 0xff];
switch (state) {
case 0:
if (d >= 0) {
value = d;
++state;
} else if (d != SKIP) {
this.state = 6;
return false;
}
break;
case 1:
if (d >= 0) {
value = (value << 6) | d;
++state;
} else if (d != SKIP) {
this.state = 6;
return false;
}
break;
case 2:
if (d >= 0) {
value = (value << 6) | d;
++state;
} else if (d == EQUALS) {
// Emit the last (partial) output tuple;
// expect exactly one more padding character.
output[op++] = (byte) (value >> 4);
state = 4;
} else if (d != SKIP) {
this.state = 6;
return false;
}
break;
case 3:
if (d >= 0) {
// Emit the output triple and return to state 0.
value = (value << 6) | d;
output[op + 2] = (byte) value;
output[op + 1] = (byte) (value >> 8);
output[op] = (byte) (value >> 16);
op += 3;
state = 0;
} else if (d == EQUALS) {
// Emit the last (partial) output tuple;
// expect no further data or padding characters.
output[op + 1] = (byte) (value >> 2);
output[op] = (byte) (value >> 10);
op += 2;
state = 5;
} else if (d != SKIP) {
this.state = 6;
return false;
}
break;
case 4:
if (d == EQUALS) {
++state;
} else if (d != SKIP) {
this.state = 6;
return false;
}
break;
case 5:
if (d != SKIP) {
this.state = 6;
return false;
}
break;
}
}
if (!finish) {
// We're out of input, but a future call could provide
// more.
this.state = state;
this.value = value;
this.op = op;
return true;
}
// Done reading input. Now figure out where we are left in
// the state machine and finish up.
switch (state) {
case 0:
// Output length is a multiple of three. Fine.
break;
case 1:
// Read one extra input byte, which isn't enough to
// make another output byte. Illegal.
this.state = 6;
return false;
case 2:
// Read two extra input bytes, enough to emit 1 more
// output byte. Fine.
output[op++] = (byte) (value >> 4);
break;
case 3:
// Read three extra input bytes, enough to emit 2 more
// output bytes. Fine.
output[op++] = (byte) (value >> 10);
output[op++] = (byte) (value >> 2);
break;
case 4:
// Read one padding '=' when we expected 2. Illegal.
this.state = 6;
return false;
case 5:
// Read all the padding '='s we expected and no more.
// Fine.
break;
}
this.state = state;
this.op = op;
return true;
}
}
// --------------------------------------------------------
// encoding
// --------------------------------------------------------
/**
* Base64-encode the given data and return a newly allocated
* String with the result.
*
* @param input the data to encode
* @param flags controls certain features of the encoded output.
* Passing {@code DEFAULT} results in output that
* adheres to RFC 2045.
*/
public static String encodeToString(byte[] input, int flags) {
try {
return new String(encode(input, flags), "US-ASCII");
} catch (UnsupportedEncodingException e) {
// US-ASCII is guaranteed to be available.
throw new AssertionError(e);
}
}
/**
* Base64-encode the given data and return a newly allocated
* String with the result.
*
* @param input the data to encode
* @param offset the position within the input array at which to
* start
* @param len the number of bytes of input to encode
* @param flags controls certain features of the encoded output.
* Passing {@code DEFAULT} results in output that
* adheres to RFC 2045.
*/
public static String encodeToString(byte[] input, int offset, int len, int flags) {
try {
return new String(encode(input, offset, len, flags), "US-ASCII");
} catch (UnsupportedEncodingException e) {
// US-ASCII is guaranteed to be available.
throw new AssertionError(e);
}
}
/**
* Base64-encode the given data and return a newly allocated
* byte[] with the result.
*
* @param input the data to encode
* @param flags controls certain features of the encoded output.
* Passing {@code DEFAULT} results in output that
* adheres to RFC 2045.
*/
public static byte[] encode(byte[] input, int flags) {
return encode(input, 0, input.length, flags);
}
/**
* Base64-encode the given data and return a newly allocated
* byte[] with the result.
*
* @param input the data to encode
* @param offset the position within the input array at which to
* start
* @param len the number of bytes of input to encode
* @param flags controls certain features of the encoded output.
* Passing {@code DEFAULT} results in output that
* adheres to RFC 2045.
*/
public static byte[] encode(byte[] input, int offset, int len, int flags) {
Encoder encoder = new Encoder(flags, null);
// Compute the exact length of the array we will produce.
int output_len = len / 3 * 4;
// Account for the tail of the data and the padding bytes, if any.
if (encoder.do_padding) {
if (len % 3 > 0) {
output_len += 4;
}
} else {
switch (len % 3) {
case 0:
break;
case 1:
output_len += 2;
break;
case 2:
output_len += 3;
break;
}
}
// Account for the newlines, if any.
if (encoder.do_newline && len > 0) {
output_len += (((len - 1) / (3 * Encoder.LINE_GROUPS)) + 1) *
(encoder.do_cr ? 2 : 1);
}
encoder.output = new byte[output_len];
encoder.process(input, offset, len, true);
assert encoder.op == output_len;
return encoder.output;
}
/* package */ static class Encoder extends Coder {
/**
* Emit a new line every this many output tuples. Corresponds to
* a 76-character line length (the maximum allowable according to
* <a href="http://www.ietf.org/rfc/rfc2045.txt">RFC 2045</a>).
*/
public static final int LINE_GROUPS = 19;
/**
* Lookup table for turning Base64 alphabet positions (6 bits)
* into output bytes.
*/
private static final byte ENCODE[] = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/',
};
/**
* Lookup table for turning Base64 alphabet positions (6 bits)
* into output bytes.
*/
private static final byte ENCODE_WEBSAFE[] = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '-', '_',
};
final private byte[] tail;
/* package */ int tailLen;
private int count;
final public boolean do_padding;
final public boolean do_newline;
final public boolean do_cr;
final private byte[] alphabet;
public Encoder(int flags, byte[] output) {
this.output = output;
do_padding = (flags & NO_PADDING) == 0;
do_newline = (flags & NO_WRAP) == 0;
do_cr = (flags & CRLF) != 0;
alphabet = ((flags & URL_SAFE) == 0) ? ENCODE : ENCODE_WEBSAFE;
tail = new byte[2];
tailLen = 0;
count = do_newline ? LINE_GROUPS : -1;
}
/**
* @return an overestimate for the number of bytes {@code
* len} bytes could encode to.
*/
public int maxOutputSize(int len) {
return len * 8 / 5 + 10;
}
public boolean process(byte[] input, int offset, int len, boolean finish) {
// Using local variables makes the encoder about 9% faster.
final byte[] alphabet = this.alphabet;
final byte[] output = this.output;
int op = 0;
int count = this.count;
int p = offset;
len += offset;
int v = -1;
// First we need to concatenate the tail of the previous call
// with any input bytes available now and see if we can empty
// the tail.
switch (tailLen) {
case 0:
// There was no tail.
break;
case 1:
if (p + 2 <= len) {
// A 1-byte tail with at least 2 bytes of
// input available now.
v = ((tail[0] & 0xff) << 16) |
((input[p++] & 0xff) << 8) |
(input[p++] & 0xff);
tailLen = 0;
}
;
break;
case 2:
if (p + 1 <= len) {
// A 2-byte tail with at least 1 byte of input.
v = ((tail[0] & 0xff) << 16) |
((tail[1] & 0xff) << 8) |
(input[p++] & 0xff);
tailLen = 0;
}
break;
}
if (v != -1) {
output[op++] = alphabet[(v >> 18) & 0x3f];
output[op++] = alphabet[(v >> 12) & 0x3f];
output[op++] = alphabet[(v >> 6) & 0x3f];
output[op++] = alphabet[v & 0x3f];
if (--count == 0) {
if (do_cr) output[op++] = '\r';
output[op++] = '\n';
count = LINE_GROUPS;
}
}
// At this point either there is no tail, or there are fewer
// than 3 bytes of input available.
// The main loop, turning 3 input bytes into 4 output bytes on
// each iteration.
while (p + 3 <= len) {
v = ((input[p] & 0xff) << 16) |
((input[p + 1] & 0xff) << 8) |
(input[p + 2] & 0xff);
output[op] = alphabet[(v >> 18) & 0x3f];
output[op + 1] = alphabet[(v >> 12) & 0x3f];
output[op + 2] = alphabet[(v >> 6) & 0x3f];
output[op + 3] = alphabet[v & 0x3f];
p += 3;
op += 4;
if (--count == 0) {
if (do_cr) output[op++] = '\r';
output[op++] = '\n';
count = LINE_GROUPS;
}
}
if (finish) {
// Finish up the tail of the input. Note that we need to
// consume any bytes in tail before any bytes
// remaining in input; there should be at most two bytes
// total.
if (p - tailLen == len - 1) {
int t = 0;
v = ((tailLen > 0 ? tail[t++] : input[p++]) & 0xff) << 4;
tailLen -= t;
output[op++] = alphabet[(v >> 6) & 0x3f];
output[op++] = alphabet[v & 0x3f];
if (do_padding) {
output[op++] = '=';
output[op++] = '=';
}
if (do_newline) {
if (do_cr) output[op++] = '\r';
output[op++] = '\n';
}
} else if (p - tailLen == len - 2) {
int t = 0;
v = (((tailLen > 1 ? tail[t++] : input[p++]) & 0xff) << 10) |
(((tailLen > 0 ? tail[t++] : input[p++]) & 0xff) << 2);
tailLen -= t;
output[op++] = alphabet[(v >> 12) & 0x3f];
output[op++] = alphabet[(v >> 6) & 0x3f];
output[op++] = alphabet[v & 0x3f];
if (do_padding) {
output[op++] = '=';
}
if (do_newline) {
if (do_cr) output[op++] = '\r';
output[op++] = '\n';
}
} else if (do_newline && op > 0 && count != LINE_GROUPS) {
if (do_cr) output[op++] = '\r';
output[op++] = '\n';
}
assert tailLen == 0;
assert p == len;
} else {
// Save the leftovers in tail to be consumed on the next
// call to encodeInternal.
if (p == len - 1) {
tail[tailLen++] = input[p];
} else if (p == len - 2) {
tail[tailLen++] = input[p];
tail[tailLen++] = input[p + 1];
}
}
this.op = op;
this.count = count;
return true;
}
}
//@UnsupportedAppUsage
private AndroidBase64() {
} // don't instantiate
}FC 准
- 这个 App 在来到公司就给我安排下来,当时真的是难到我了,这 App 回来的数据,都是加密过的,方法也跟不到。
- 然后多次弄的都要放弃了,这时候发现了另外一个突破 App,嘿嘿。。
开始
- 首先通过 FD 抓包,修改掉返回的数据,因为我发现这个 App 返回的数据内是有
iv这个值的。
{
'data': 'mbMe6kGkD3k******',
'iv': 'YWZiMjNiZW***',
'key': 'rKnvPMKv/wwD/w***',
'version': '2'
}- 我们知道在 非对称加密算法 Rsa 中,解密是需要一个 iv 值的,并且 Java 的语法是严谨的,如果返回的数据不正确,肯定会报错。
- 尝试一下,修改返回值,让 App 读取不到数据,看看报错的调用栈。(最后发现真的可以跟到解密位置。)

- 看到成功触发异常,并且出现了很重要的一个关键字:
数据解密异常 - 因为 App 没有壳,我们直接拖入反编译工具,搜索源代码。

- 可以看到返回值是一个 byte 数组,那么肯定在外层还有一个解密方式。

- 那现在就知道了传入的顺序,以及最终返回的
byte数组,怎么进行最终的处理。 - 现在回归逆向本源
缺啥补啥最终得到下面这么多的文件。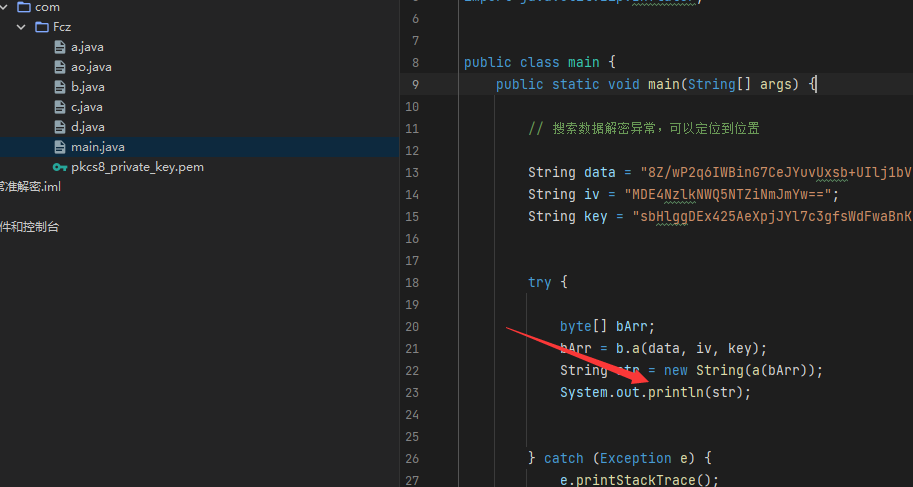
- 这个 APP 用了一个
Rsa+Aes - 这个 APP 非常适合练手 记录一下 是第一个自己破解的 APP 以后只会越来越难
FC 准
上面那个是老业内版本 现在这个就是最新版 梆梆企业壳 混淆
有几个恶心的地方
frida注入的时候 七搞八搞 换版本 都没办法注入两次- 并且第一次注入的时候 必须
hook[69929, 67957, 376825, 393121, 396429, 404949, 374245, 521065, 373257]这些线程id - 并且不是百分百进去 一直重复关闭打开关闭打开才行
- 玄学啊 = =
- 然后采用的就是先注入 然后手动在控制台写
hook代码- 可以提前写一个
printLog函数 然后用这个函数进行输出 如果直接在控制台写代码console.log()好像不会输出
- 可以提前写一个
- 然后把梆梆壳扒了之后 各种堆栈开始找 最终会找到下面这两个位置
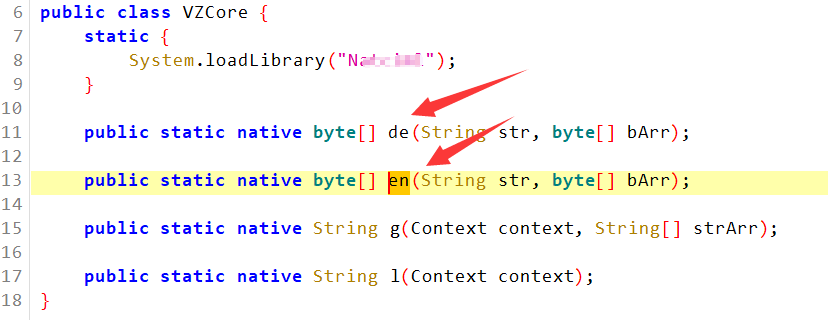
- 然后上
unidbg开始调用so发现他读取了maps文件内容 我们在内存中pull一份下来 用下面的代码打开
@Override public FileResult<?> resolve(Emulator emulator, String pathname, int oflags) { if ("/proc/self/maps".equals(pathname)) { return FileResult.success(new SimpleFileIO(oflags, new File("unidbg-android/maps"), pathname)); } return null; }- 然后继续 会出现一些包名的检测 要什么补什么
@Override public DvmObject<?> getStaticObjectField(BaseVM vm, DvmClass dvmClass, String signature) { switch (signature) { case "com/feeyo/vz/application/Application;": return vm.resolveClass("com/feeyo/vz/application/Application").newObject(signature); } return super.getStaticObjectField(vm, dvmClass, signature); } @Override public DvmObject<?> callObjectMethodV(BaseVM vm, DvmObject<?> dvmObject, String signature, VaList vaList) { switch (signature) { case "com/feeyo/vz/application/Application->getPackageName()Ljava/lang/String;": return new StringObject(vm, PackageName); case "com/feeyo/vz/application/Application->getPackageManager()Landroid/content/pm/PackageManager;": return vm.resolveClass("android/content/pm/PackageManager").newObject(signature); } return super.callObjectMethodV(vm, dvmObject, signature, vaList); }- 最终运行结果
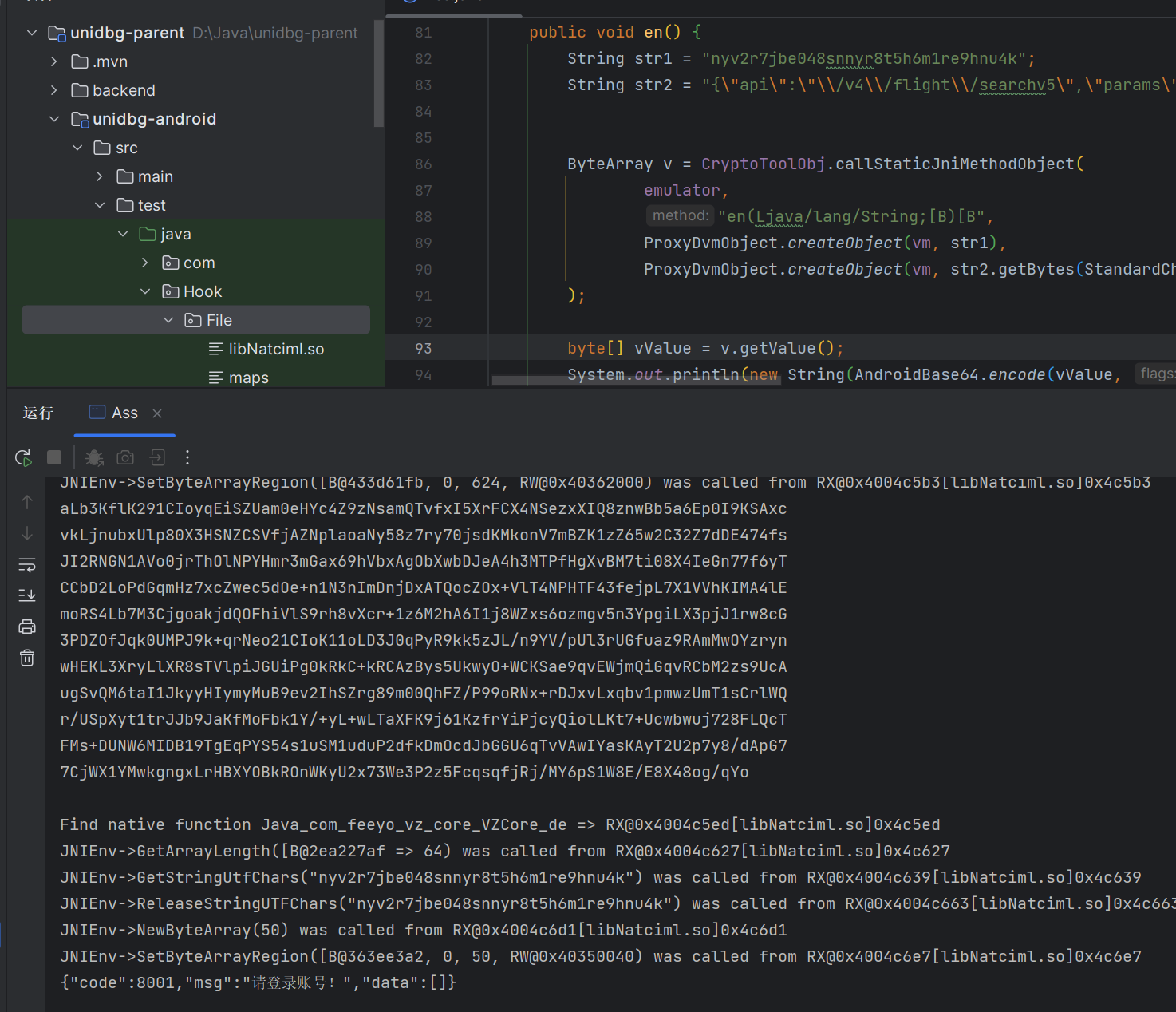
tips
- 这个 app 允许不登录的情况下 查询两次航班信息 这个次数是根据
uuid绑定的 如果已经耗尽次数 可以清空app信息再打开 就可以再查两次 - 猜测就是在
app启动的时候 会发送请求激活uuid然后这个 id 会保存着有一个查询时效间隔这里确实是这样 因为我已经搞定了
- 这个 app 允许不登录的情况下 查询两次航班信息 这个次数是根据
深圳航空 APP
目前还在破,完全成功之后再详细记录.不知道为什么有的人可以 dump 出来企业壳的详细信息.不过目前学到很多
- 2022 年 6 月 8 日 12 点 04 分
- 目前项目已经完结
第一步
- 首先上来就是一个爱加密企业壳
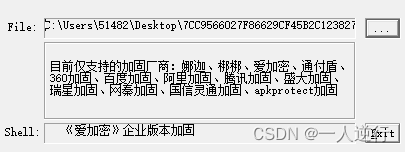
首先用 root 手机+寒冰大佬的 fr 工具 dump 出来 dex
dex 其实就是 java 的源代码,用 jadx 查看
然后发现很多方法还是被抽取,但是可以看到核心的方法是出来了。
下面中绿色部分表示反编译失败,应该是被抽取的方法。
- 抽取就是只有在运行的时候壳代码才还原回去,不执行的时候函数体会被抽走,直接 dump 就是空。
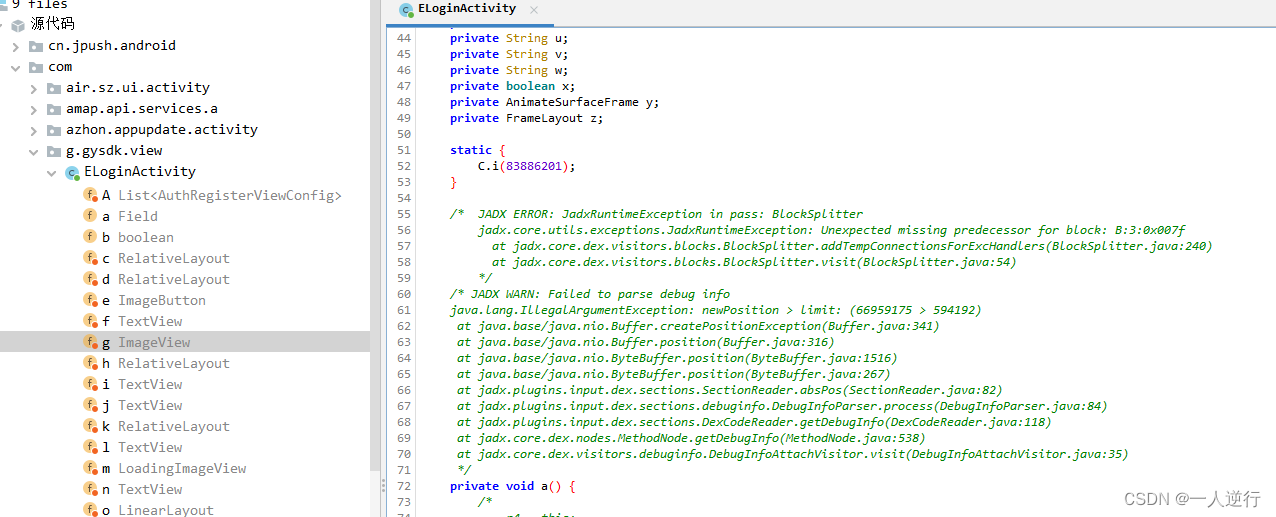
- 抽取就是只有在运行的时候壳代码才还原回去,不执行的时候函数体会被抽走,直接 dump 就是空。
因为这个 app 没有证书检测,所以可以直接抓包。
- 这三条都是 航班信息 分别查询的是不同的航司

- 至于其中的参数 都是明文 就没什么好说的了 直接复制即可
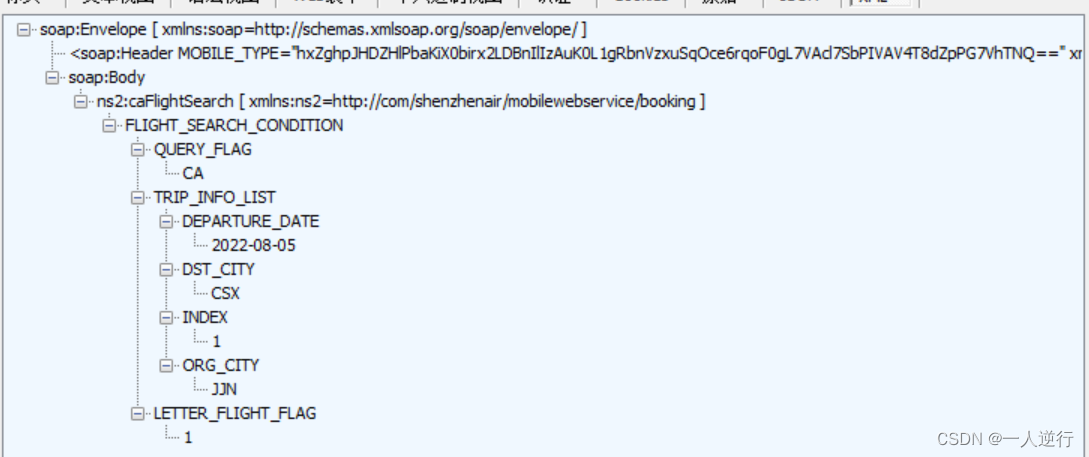
抓包分析出来主要参数就是
MOBILE_TYPE
package com.neusoft.****.model.encrypt;
import java.text.SimpleDateFormat;
import java.util.Locale;
public class KeyGenerator {
private static final String MD5_KEY = "*****";
private static final String SECURITY_KEY = "s*air******";
private static final SimpleDateFormat YMDHMS = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
public String getNewKey() {
return MD5Util.MD5Encode(MD5_KEY);
}
public String getKey() {
return CryptUtility.base64Encode(CryptUtility.encrypt((new KeyGenerator().getNewKey() + String.valueOf(((double) System.currentTimeMillis()) / 1000.0d)).getBytes(), SECURITY_KEY.getBytes())).replaceAll("\n", "");
}
}- 内部一个固定参数,加时间戳,加固定参数,然后用一个
DES算法加密 - 第一阶段出来一个
MOBILE_TYPE就可以查到航班信息了。 - 这里要注意登陆状态进行查询,避免后期重新做。
第二步
- 来到第二步,生成订单的时候,会发现参数变了,不再是明文 xml 了
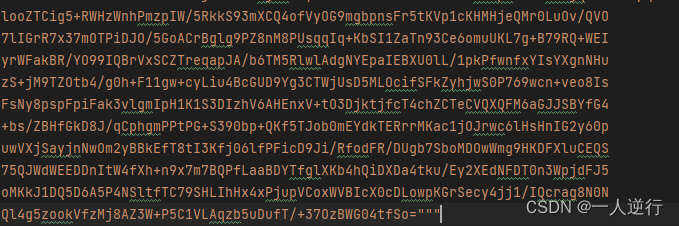
- 看到这种乱码一开始真的没地方下手
- 但已经破出来,经验可以分析出来一些东西。
- 首先采用的 DES 算法,我们知道 DES 是对称加密,前端用了什么密钥,后端就要用什么密钥才可以解密,那么我在请求头里面删删减减发现密钥不在请求头,最终发现就是在这段乱七八糟的密文里面。
- 首先盲猜是 Base64,然后发现真的是,但是后面一段还是乱码。

- 可以看到前面有一个字符串,通过抓包拦截工具发现,其实就是随机的。
- 那么后面一段是什么,通过通用拦截工具,跟栈之后找到下面这段代码。
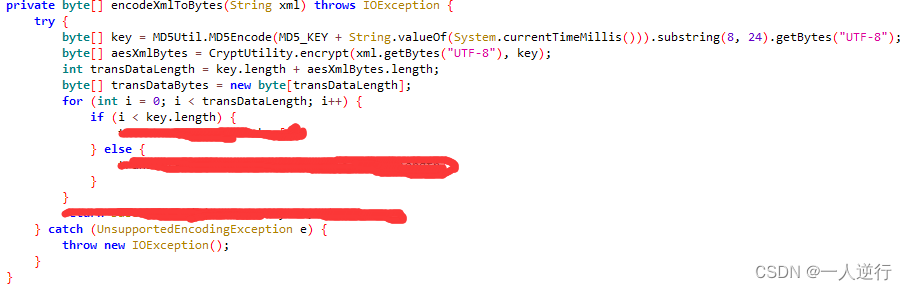
- 这里涂掉一部分,只提供思路,项目公司还在用,不方便完全透露。
- 然后让 java 同事反写出后端解密算法
- 调用接口解密出内容如下
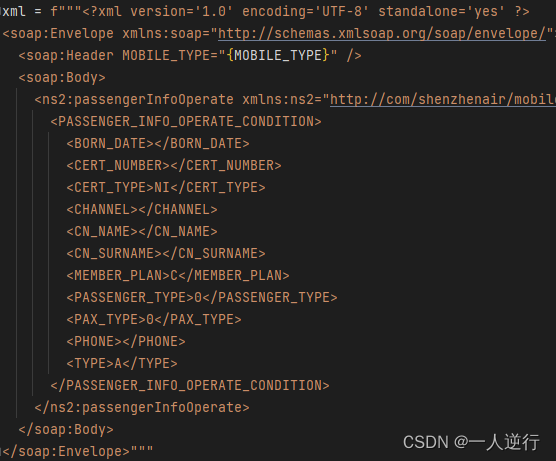
- 目前就是加密,解密,所有参数都解出来了,就差写接口和风控了。
注意事项
- 生成订单的时候可能直接提示 生成订单失败 请重新登录购票 三种可能
- 生成订单和航班查询间隔太长了
- 查询和生单的时候使用的不是一个账号 或者 账号信息携带的不对
- 在打开 app 的时候 会发送一个请求 激活账号 这和 查询航班是分开的 需要重写这个请求
- 生单的所有信息 都要完全对应 错一个都不行
- 价格采用 五舍六入 取整
- 还有一个难点就是优惠券的绑定 有的优惠券 只能领取一张 但生单要很多人一起 这就要自己取舍了
- 下面这三个参数 在代码中都不知道在哪个位置实现了 但最后发现 不要带这三个参数也可以 所以这里后期可能是检测点
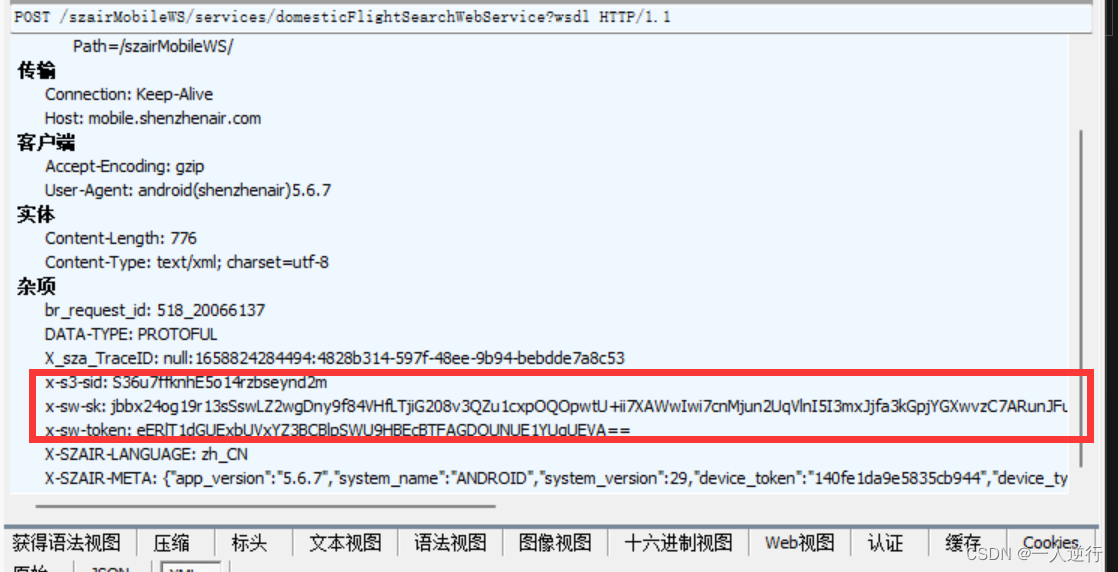
- 2022 年 10 月 19 号更新 有需求 又来破解了一遍 底层完全没变 还是 xml 加密也没变
- 之前有一个激活账号下单权限的请求 现在也有 但现在这个请求返回的
set-cookie里面有一个session生单就要用 要不然会显示会话超时(之前是显示请重新登陆) - 然后生订单的时候会有三种情况的报错
- 一个什么都不返回
- 一个显示短信验证码失效 (但实际没有掉线)
- 还有一个显示会话超时 应该跟 session 有关系
- 之前有一个激活账号下单权限的请求 现在也有 但现在这个请求返回的
去哪儿 App
- 终于搞出来了 在此记录一下
- 期间遇到的问题还是花了点钱找人询问了一下 当自己进步的花销
第一步
- 抓包就是一个难点 乱码 会导致找到了解密算法 也没办法直接复制密文解密
- 最大的特点就是前面都是
a1907并且后面跟着乱码 会导致 后面都不显示出来
- 最大的特点就是前面都是
- 这时候就要完全找到加密前的数据 在加密之前就进行
hook - 最终跟到如下位置
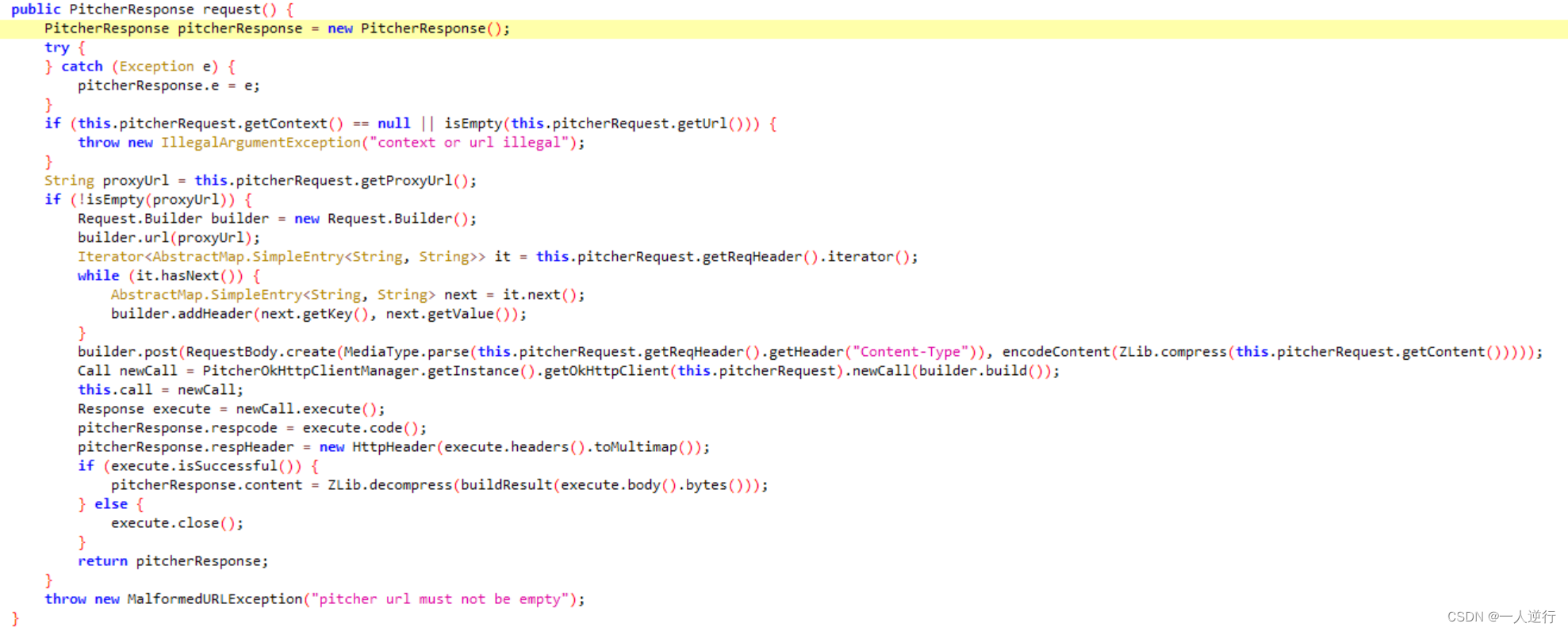
- 通过
ZLib.compress进行一次加密 然后encodeContent再进行一次加密 - 分析之后
ZLib.compress可以直接复制java层代码就可以运行 encodeContent跟进之后发现是so层函数sand是加密函数drift是解密函数- 所以转用
unidbg进行调用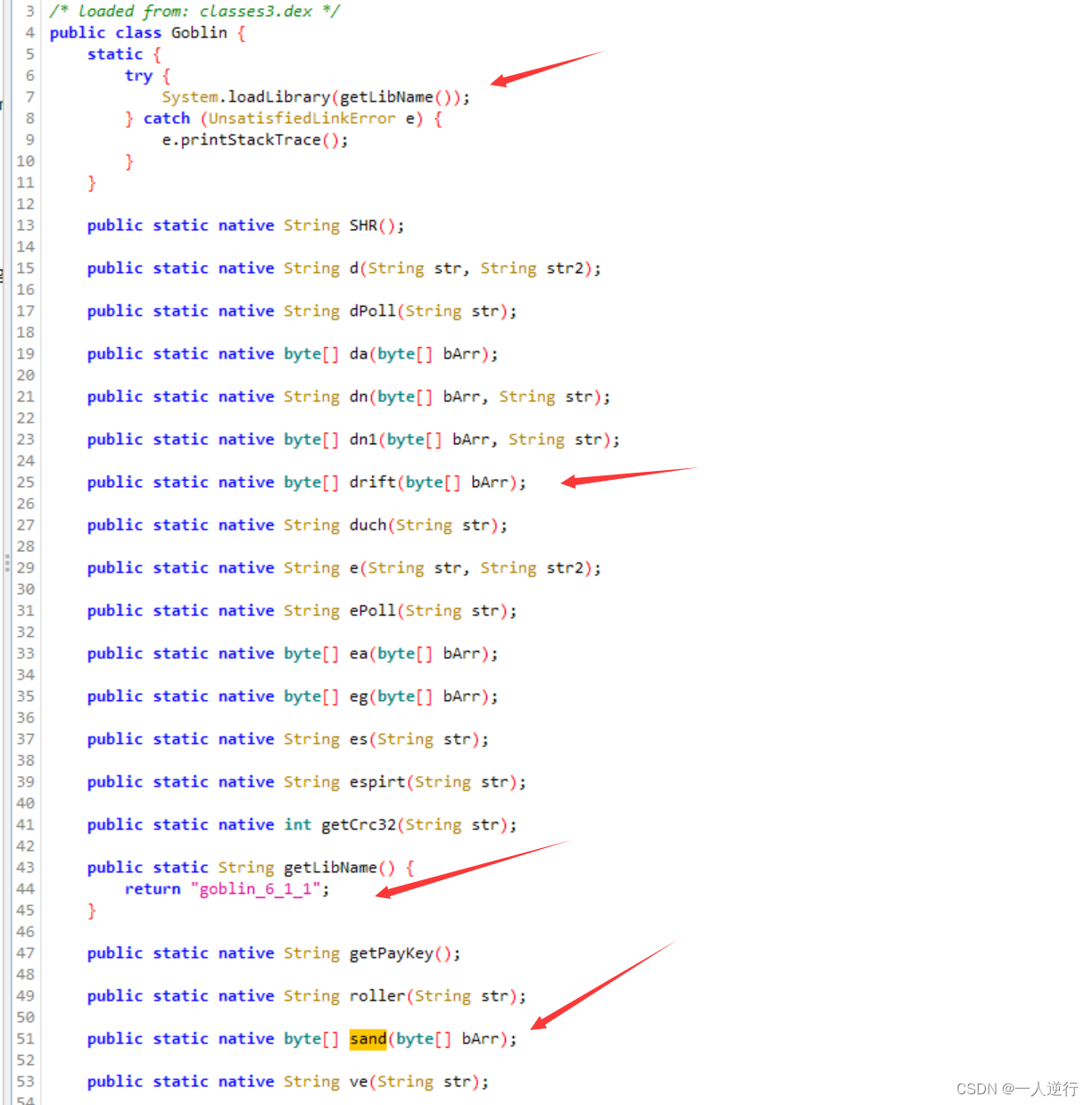
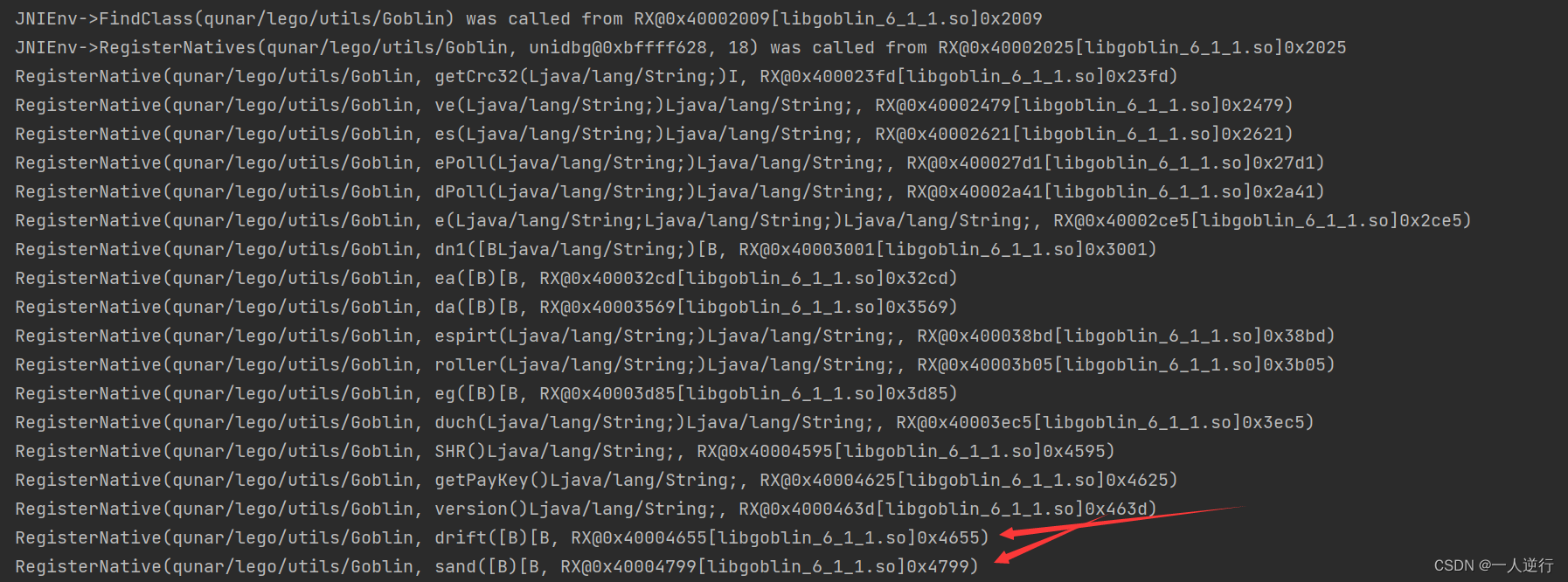
- 注册成功 现在拿到了加密解密函数 就差密文
app没办法动态调试 所以只能frida hook - 我们知道
compress进行的是第一次加密 那么传入的内容就是 明文状态下的bytes数组可以转换回来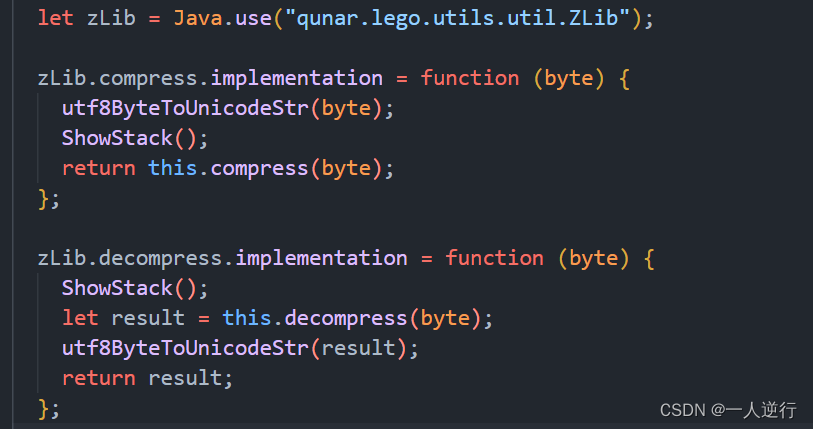
- 通过注入上面的代码 拿到 明文为以下内容
hdogチ{"route-type":"hotdog","data-type":"normal","version":"1.0.0","params":{"b":{"start":0,"length":2},"c":{"start":2,"length":602}}}{}{"adid":"***","brush":"{\"lt\":\"0\"}","*******","resolution":"1080x2210","sid":"**-**","t":"**","tsv":"30","uid":"**","un":"","usid":"","vid":"**"} - 去掉前面的
hdog可以发现后面是三个字典 第一个字典中指明第二个和第三个字典的长度 - 第二个字典是主要信息 第三个字典好像是后端要用的一个接口信息 那么带上去走一下流程 看看是否返回数据
{"bstatus":{"code":0,"des":"成功","action":null},"data":{"status":0,"ext":null,"resultStr":null,"builder":null,"token":"B2E50EE5199F****HAyzriRLahuzArVwNu88="},"global":null,"ext":null} - 返回成功 注意一下 如果你发送的信息是不正确的
那么服务器会返回一段错误信息会死循环 导致卡死- 这里卡死 后面跟调用栈发现 是在
java层有一个死循环 导致卡死在里面了 - 自己改写了代码 如果循环执行超过5秒 就退出循环 解决卡死问题
- 这里卡死 后面跟调用栈发现 是在
- 可能会遇到一种字典内包含一个参数
becheck一眼看去很像MD5但不知道是什么加密的 最终发现也是在so层进行的加密sepa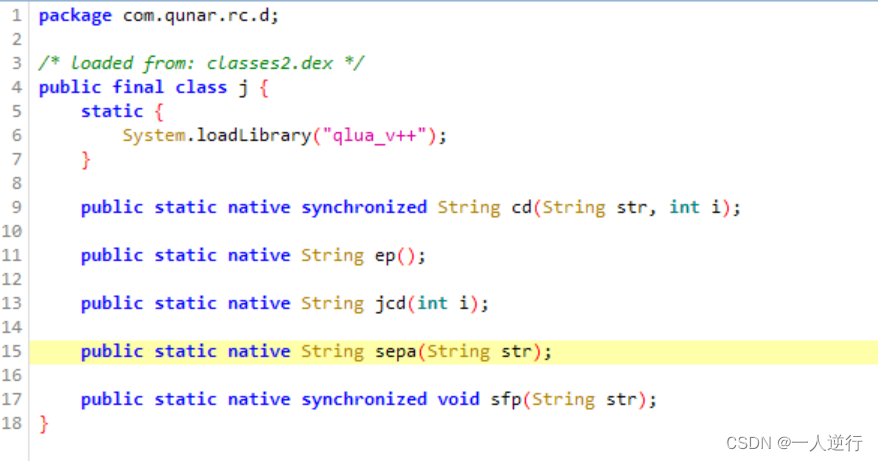
- 只要
hook传入的明文 直接带上去请求就行 不需要进行这一步加密
登录
- 登录的加密和解密流程是一样的 但是在登录里面有两个参数
publicKeypassword - 其中
password就是明文的验证码 ( 因为这里用的是验证码登录 ) publicKey是之前发送了一个请求返回的 其中还有一个token下一个请求要一起带上明文的token和加密后的密文 才可以请求成功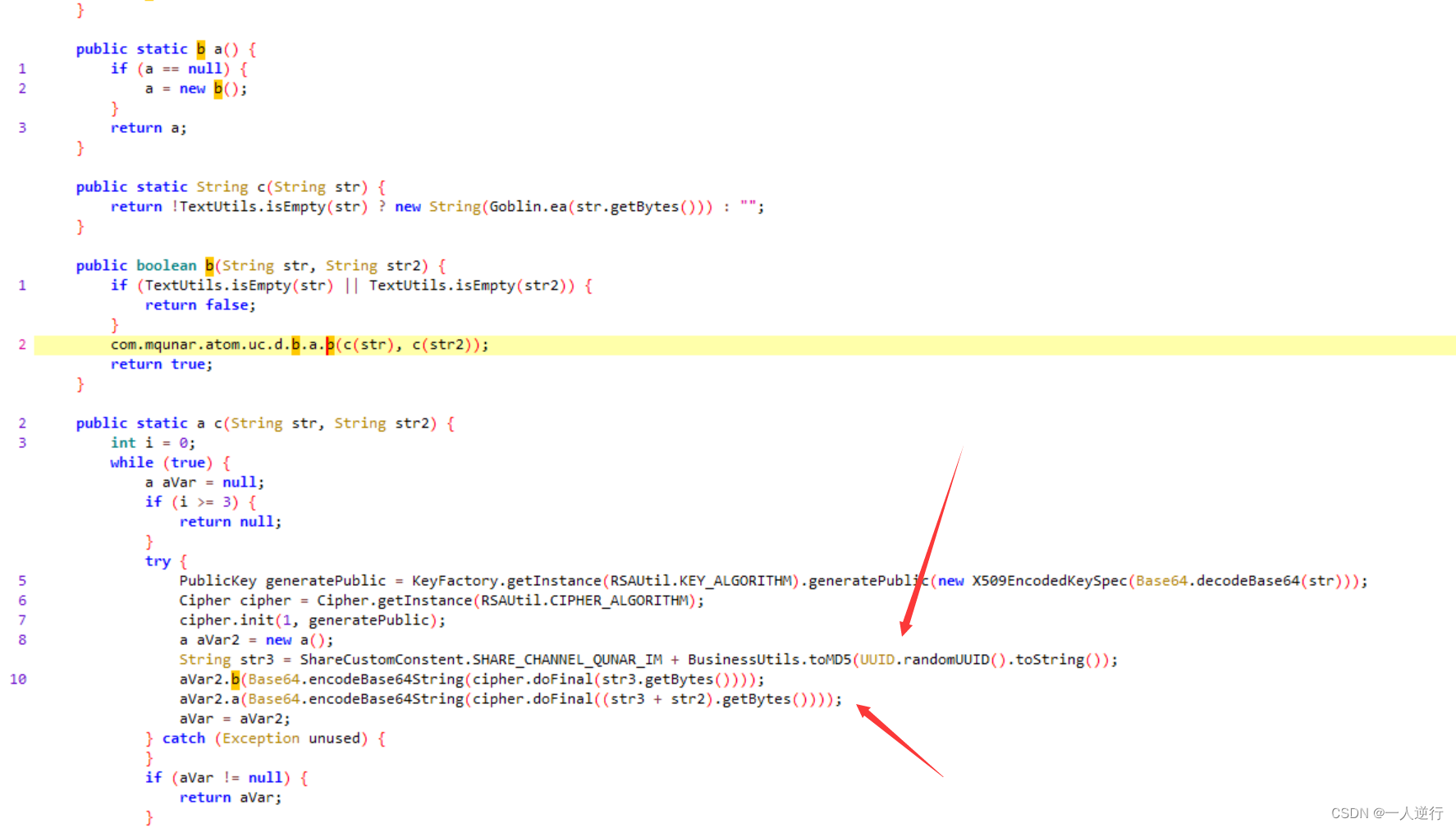
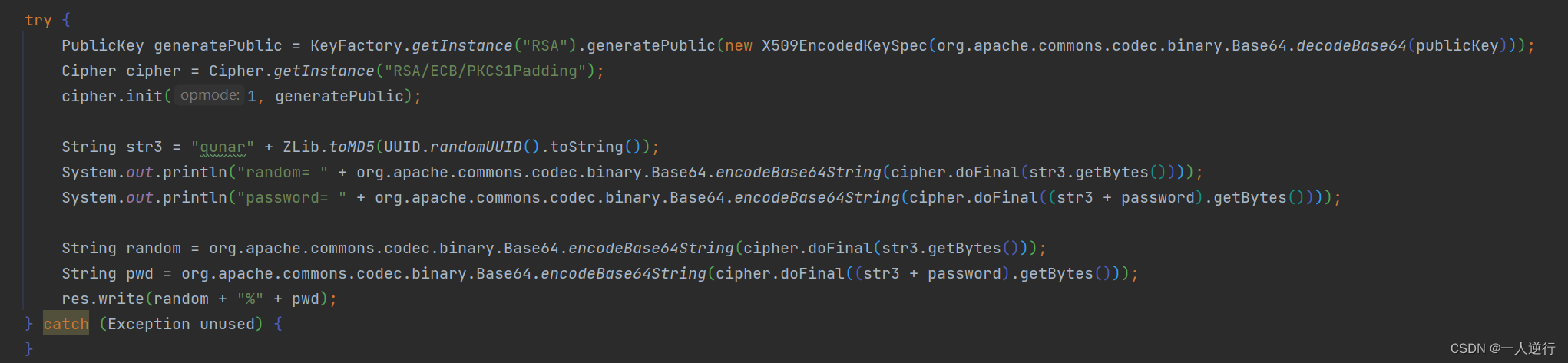
注意事项
- 订单生成页面有一个超大的
json是一个难点 - 航班查询那有一个
bookingkey这个就包含航班的所有信息 自己只要再提供乘机人和联系人就行了 - 价格上是有账号优势
2022年9月4日 公司发现一个新的东西 增加了一个接口 然后发现生单有的成功有的失败- 最终通过一天的排查 发现这个接口的价格并不是显示出来的价格
- 所以我的代码层是没有错的 就是价格定位错了 浪费了周末的两天休息时间
更新
- 2022 年 10 月 15 日 去哪儿 app 的最新版本更新之后 把
so改了一下 但底层算法没变 也就是还可以用之前版本的so来加密最新版本的字段进行请求 - 增加了
frida检测 注入就闪退
同程 APP
这个 app 没有壳 但是最新版无法 frida 附加 附加就退出了
- 可以通过
hook线程的方式kill掉检测线程
- 可以通过
首先前面都没有任何加密 信息都是密文传输
直接跳到付款位置 支付的地方

根据上面两个字段 猜测跟到如下位置
下面的包只是引用了一个美团的热更包 在
java层用不到 全部删掉org.bouncycastle.crypto是一个maven包 直接引入就可以用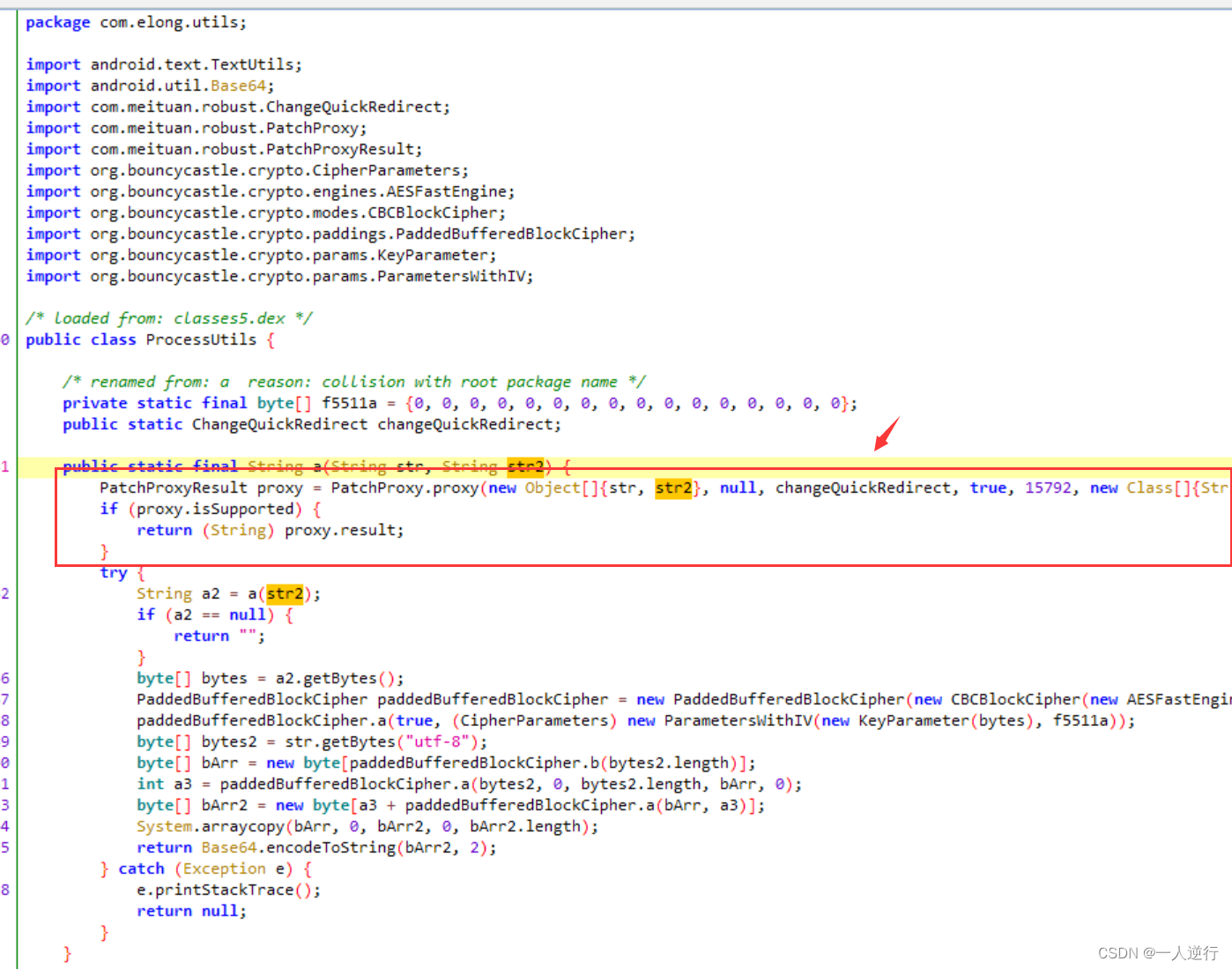
第一个参数是需要传递的信息 第二个参数是固定的
QOthSMQayhTz1RGU但只带上加密的
r还是不行 发现请求头也变了 其中有一个md5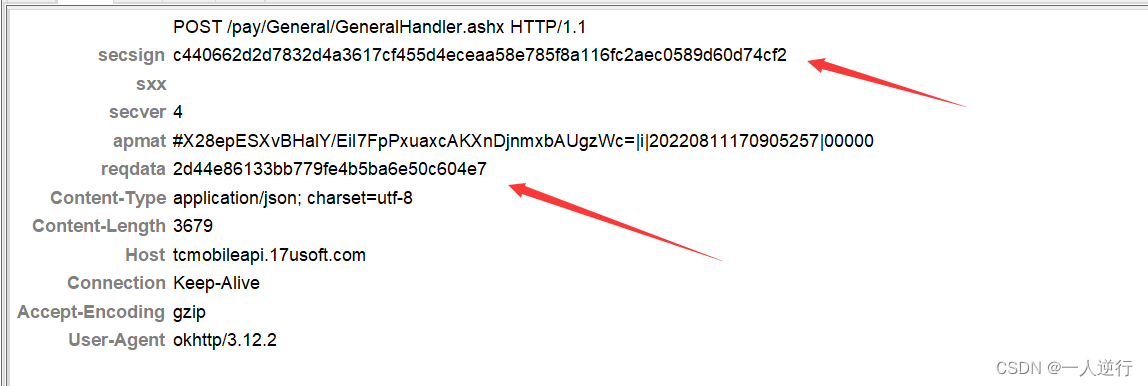
其中
secsign是在so层进行计算的 没有任何检测unidbg直接调用成功- 这里不要管这个字段 写死服务端也不会进行验证
so层函数是k0
- 这里不要管这个字段 写死服务端也不会进行验证
下面那个
reqdata和请求体中的r是对应的将r的明文体转字符串 加上"4957CA66-37C3-46CB-B26D-E3D9DCB51535"进行MD5还进行了一些自定义操作
json字段分析clientInfo这个连接信息就是关于客户端和用户的 在不改变用户的情况下 写死即可payInfo这个字段是在你点支付的那附近抓包 他会发送一个订单号 会拿到这个字段 后面全程携带就行confirmSerialId这个类似一个安全码 你只要按顺序请求就会返回 不是加密字段memberId这个和用户绑定 修改会报mi错误header字典内serviceName我们发送的请求都是一样的url是通过这个 区别数据包的处理方式reqTimesign这个两个字段 是包含一个时间戳的 其中sign通过以下方式进行拼接AccountID={account_id}&ReqTime={_time}&ServiceName={service_name}&Version={version}8874d8a8b8b391fbbd1a25bda6ecda11然后进行app的md5加密 然后把内部加密的时间戳 放在reqTime里面
- 至此所有加密字段都弄完了
GT 管家
- 上来抓包有两个问题
- 无法直接抓包 用
frida注入hook掉SSL认证 - 抓包各种分析之后 发现一个参数
sid- 我们要查询数据 就会有这个
sid现在已经破了 才知道他是从so层算出来的
- 我们要查询数据 就会有这个
- 新版本 增加了检测 需要
hook掉检测线程
- 无法直接抓包 用
- 外部一个
梆梆企业版的壳 - 脱壳机 一顿操作破掉壳然后搜索会定位到下面这个位置
- 其实我这里还分析了好久
- 因为他算法是一个接口 然后另外一个类实现了这个接口 但是
- 实现的这个类 是调用了初始化的时候 传进来的另外一个实现了这个接口的类 就很绕 反正最终会跟到下面这个位置
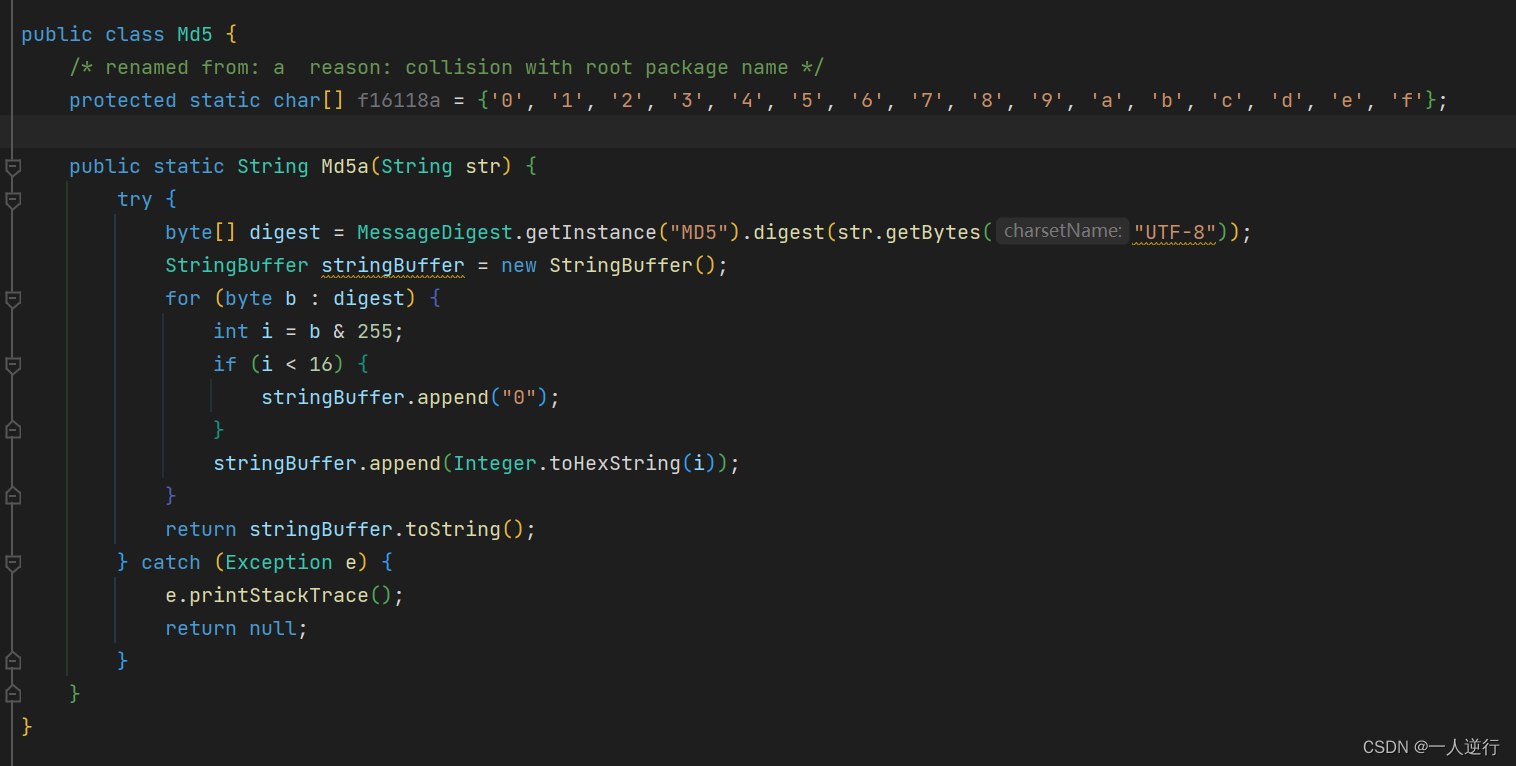
- 这里看到是
so层 那我们上Unidbg配置好信息之后 启动报错 发现了在报错之前 获取了一些签名信息

- 我们拖到
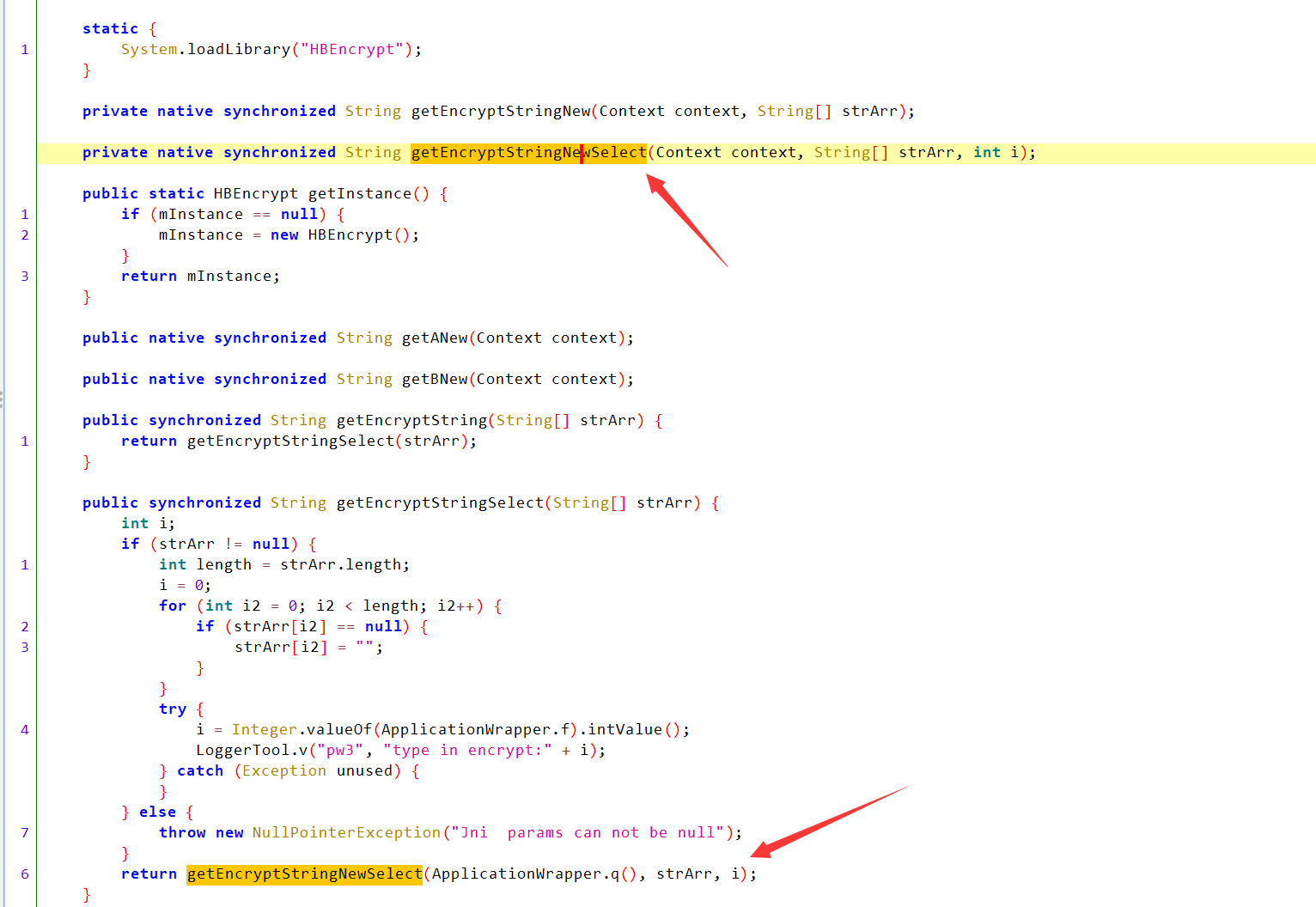
ida分析- 因为
Unidbg已经帮我们分析出了具体位置 Find native functigetEncryptStringNewSelect => RX@0x400033c0[libHBEncrypt.so]0x33c00x400033c0为基址0x33c0为偏移 直接G跳转- 看到一个
exit(0)在签名不对的情况下 退出 - 那我们把它
hook掉 让他返回0
- 因为
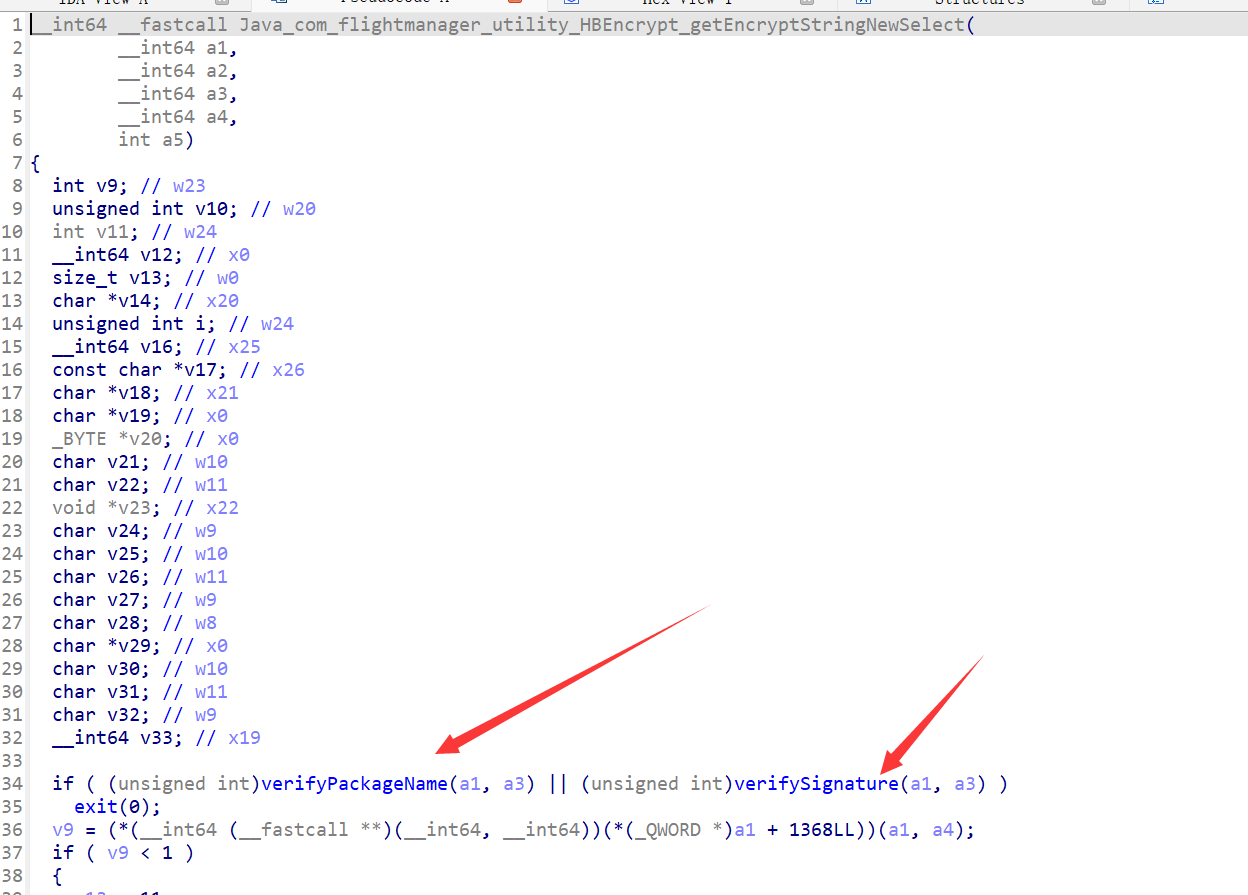
// 这里因为函数列表可以直接看到这两个函数 才可以直接ByName 要不然就要自己算偏移了
IHookZz hookZz = HookZz.getInstance(emulator);
hookZz.replace(module.findSymbolByName("verifyPackageName"), new ReplaceCallback() {
@Override
public HookStatus onCall(Emulator<?> emulator, HookContext context, long originFunction) {
// 自定义返回类型
return HookStatus.LR(emulator, 0);
}
});
hookZz.replace(module.findSymbolByName("verifySignature"), new ReplaceCallback() {
@Override
public HookStatus onCall(Emulator<?> emulator, HookContext context, long originFunction) {
// 自定义返回类型
return HookStatus.LR(emulator, 0);
}
});// 然后通过下面的代码 HOOK到核心的入参
let HBEncrypt = Java.use("com.flightmanager.utility.HBEncrypt");
HBEncrypt.getEncryptStringNewSelect.implementation = function (a, b, c) {
let result = this.getEncryptStringNewSelect(a, b, c);
console.log("a: " + a, "a length: " + a.length);
console.log("b: " + b, "b length: " + b.length);
console.log("c: " + c, "c length: " + c.length);
console.log("result: " + result, "result length: " + result.length);
return result;
};
Tips 在这个例子中 基本类型不要用
ProxyDvmObject.createObject()除了用
hookzz替换原始函数 我们还可以直接修改PC寄存器 跳过检测的判断 连检测函数都不执行当我们
0x33EC的时候 代码开始检测部分CBNZ跳转loc_366C直接结束执行- 那么我们修改
PC寄存器 跳转到if语句之后的汇编代码 开始执行
- 那么我们修改
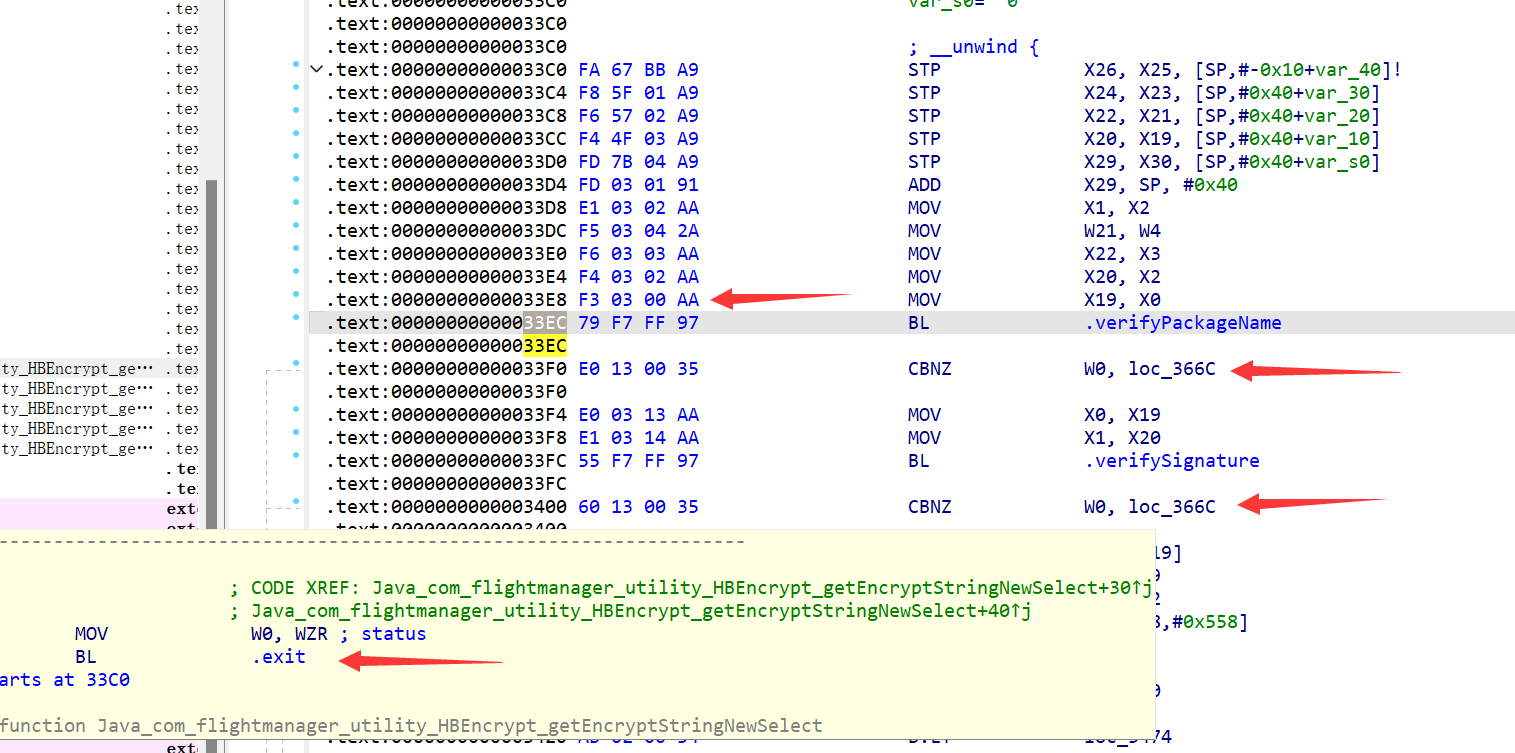
// 这里提供另外一种简洁的方式 修改PC寄存器 跳过IF语句的执行
emulator.getBackend().hook_add_new(new CodeHook() {
@Override
public void hook(Backend backend, long address, int size, Object user) {
emulator.getBackend().reg_write(Arm64Const.UC_ARM64_REG_PC, module.base + 0x3404);
}
@Override
public void onAttach(UnHook unHook) {}
@Override
public void detach() {}
}, module.base + 0x33EC, module.base + 0x33EC, "obj");


